
What Is Edge Computing, And Why Is It Important?
Introduction
Edge computing is an architecture that involves keeping data near the user and processing information at multiple locations throughout your network or infrastructure. There are many reasons why edge computing has become so important, including:
Edge computing is a type of distributed computing.
Edge computing is a type of distributed computing. Distributed computing uses multiple nodes to share and process data, with each node handling different parts of the task. Edge computing is a form of distributed computing that takes place at the edge of a network–that is, in places where data originates or ends up before it gets sent elsewhere on its journey through your organization’s systems.
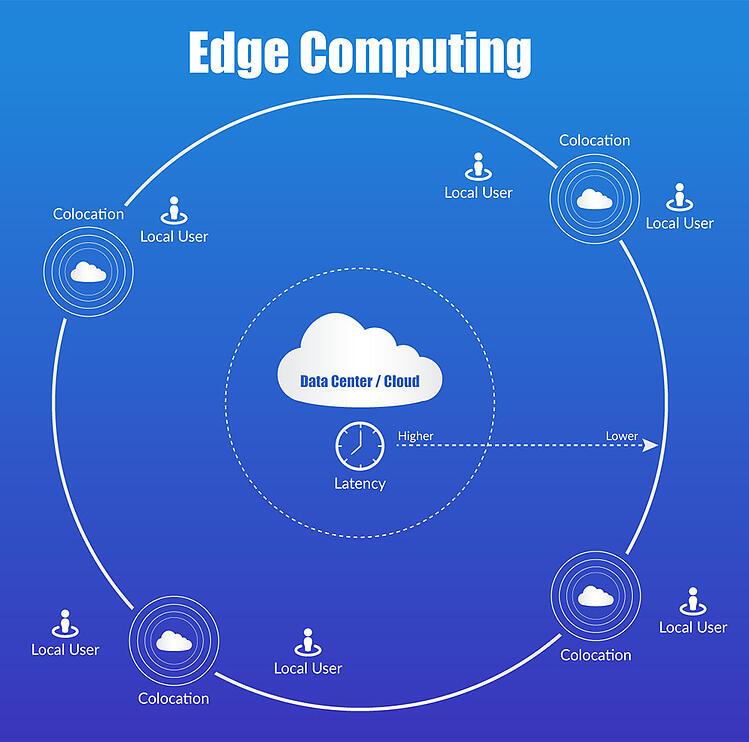
The term “edge” refers to the place where data enters or leaves your network or infrastructure.
The term “edge” refers to the place where data enters or leaves your network or infrastructure. It’s a broad concept that can refer to anything from a gateway, router, switch or other device on your network to a cloud service provider that provides storage and compute resources. In this article we’ll focus on the former–how edge computing enables more data processing to happen closer to its source.
Edge computing is a distributed computing architecture where information processing happens near where it originates (at “the edge”) rather than in centralized locations like data centers located far away from users and devices generating this information. This architecture enables faster access times because distances between sources/sinks are shorter; less latency since there are fewer hops needed before reaching endpoints; greater reliability through redundancy built into each component within an interconnected system; reduced costs associated with transporting large amounts of information over distance (e-commerce companies like Amazon Web Services benefit greatly from this); increased privacy protection through encryption at every step along transmission paths so only authorized parties can access sensitive data without compromising its integrity during transit
Edge computing is often used in conjunction with the Internet of Things (IoT).
Edge computing is often used in conjunction with the Internet of Things (IoT), since it’s a way to process data at the edge of your network. The IoT refers to devices connected to networks and connected to each other through sensors, which collect large amounts of information that needs to be processed quickly. Edge computing allows companies and organizations to analyze this data locally at each device rather than sending all their information back up onto an application server or cloud provider. This makes it possible for companies like Amazon Web Services (AWS) or Microsoft Azure Cloud Platform–both providers of cloud services–to host their own IoT applications without having as much infrastructure investment required by traditional on-premises systems.
Edge computing can involve processing information at various points, including storage and computing nodes on the edge of a network, as well as closer to where data originates and ends up.
Edge computing is a term used to describe the use of distributed computing and storage resources at the “edge” of a network, or closer to where data originates and ends up. Edge computing can be used for various tasks including processing and analytics, storage, security and more.
Edge computing can involve storing data locally (on an edge device), processing it there before sending it back over the network or even doing some computation on the device itself. This allows companies to make better use of their existing infrastructure by reducing latency between users and servers while also reducing costs associated with hosting large amounts of information in centralized locations such as data centers.
Edge computing allows businesses to store data locally instead of in remote servers.
Edge computing is the process of storing data locally and processing it with microservices closer to users or sensors. This allows you to bypass cloud providers and their servers, which can be expensive and slow.
Edge computing allows you to store data on devices that are close to where it needs to be accessed or processed–for example, in an autonomous car’s system or in a smart home security system. It also lets you process information more quickly by using less powerful computers than those required for cloud-based services (which require heavy-duty CPUs).
Edge computing has many uses within businesses: It can help collect data from remote locations such as oil rigs or farms; it can improve customer experience by providing faster response times when customers interact with your business digitally; and it can even help streamline operations like inventory management by keeping track of what items need replenishing as soon as they run out rather than waiting until after hours when employees get back into the office next day!
In some cases, devices at the edge of networks are capable of uploading data directly to cloud providers themselves.
Edge computing can be used to process data at the edge of a network, either by storing it locally or processing it through microservices closer to users or sensors. In some cases, devices at the edge of networks are capable of uploading data directly to cloud providers themselves.
In many cases where an organization has deployed an edge-computing architecture–for example, if you’re using AWS Greengrass on your IoT devices–you don’t need cloud providers anymore because they’re doing their job in tandem with yours: processing data and acting on it without requiring input from another party (in this case, Amazon).
Cloud providers aren’t always necessary with an edge-computing architecture because data can be stored locally or processed by microservices closer to users or sensors.
Cloud providers are a scalable, cost-effective solution for storing and processing data. However, cloud providers aren’t always necessary with an edge-computing architecture because data can be stored locally or processed by microservices closer to users or sensors.
With an edge-computing architecture, you may need fewer servers in the cloud and more on premises–and this is where we run into problems with cost savings: You might have fewer servers overall but they’ll be more expensive per unit than the ones you would have used in your original plan.
You can use edge computing for various tasks in your business
You can use edge computing for a variety of tasks in your business. For example, if your company is using IoT devices to collect data from remote locations, edge computing allows you to process this information at the edge of your network or infrastructure instead of sending it back to a central hub. This saves time and resources while ensuring that all relevant details are available right away.
Edge computing also makes it easier for organizations to store data locally instead of relying on remote servers, which could become unavailable due to issues like power outages or network congestion. By keeping everything onsite, businesses can keep functioning even when something goes wrong with their internet connection!
Conclusion
As you can see, edge computing offers many benefits for businesses. It’s a flexible technology that can be used in a variety of ways and is especially useful for IoT applications. The ability to store data locally or process it at the edge of your network means that you don’t have to rely on cloud providers as much–and that means more control over how data is handled and processed.